Sistemas de recommendação - Neural Collaborative Filtering
Com demo sobre Neural Collaborative Filtering



- Neural collaborative filtering
- TL; DR
- Sistemas de recomendação
- 💁♂️ Collaborative filtering
- 🧠 Neural collaborative filtering
- 💻 Demo
- Os dados
- O modelo (Neural Collaborative Filtering)
Neural collaborative filtering
TL; DR
Sistemas de recomendação
🥅 Objetivo
O objetivo é gerar recomendações para um usuário. O sistema de recomendação perfeito recomendaria a um usuário um item que ele gostaria, e que a pessoa não chegaria ao item sozinha. Portanto, um modelo que recomenda os itens mais populares para todos os usuários não é considerado um bom sistema de recomendação - as recomendações não são personalizadas.
O resultado principal de um modelo seria, por exemplo, os 10 principais itens que um usuário pode gostar e ainda não viu.
📚 Dados
Os dados podem incluir informações sobre o usuário (ou seja: idade, sexo, informações sobre compras anteriores), mas deve incluir informações da interação entre usuários e itens - se um usuário comprou/gostou/avaliou um item. Essa interação costuma ser chamada de feedback. Existem dois tipos diferentes de feedback: explícito e implícito.
💬 Feedback explícito x implícito
Feedback explícito é a interação que o usuário fornece intencionalmente - classificações de 5 estrelas em um produto, a 👍 em um produto etc.
Feedback implícito ocorre sempre que temos uma "dica" das preferências do usuário. Comprou, viu um filme, etc. Recebemos um interesse entre o usuário e o item, mas não um feedback concreto - se o usuário realmente gostou do item (só porque eu vi o filme, não significa que gostei).
Como se poderia imaginar, o feedback explícito é mais informativo do que o implícito. Mas, na maioria dos casos, esses dados não estão prontamente disponíveis ou são muito escassos. No restante desta postagem, vamos nos concentrar em situações nas quais recebemos feedback implícito.
Ao trabalhar com feedback implícito, antes de dividir os dados em teste e treinamento, precisamos fazer a suposição de que toda interação observada é positiva e a ausência de interação é negativa. No exemplo, todos os filmes que assisti eu gostei e todos os filmes que não assisti eu não gostaria (não é realista, mas necessário para definir o problema).
🔪 Divisão de "test" e "train"
Depois de reunir todas as informações, temos todos os usuários, itens e interações. Podemos colocá-los em uma matriz - também conhecida como matriz de interação.

Ao construir o teste, uma ideia é manter uma interação entre um usuário e um item e tentar prever isso. Pela imagem acima, poderíamos impedir a entrada do casal ruivo Shrek para o teste.
Pode-se fazer isso amostrando uma interação aleatoriamente para cada usuário, mas é interessante ter em mente a taxa de teste do trem e a possibilidade de vazamento de dados. Pode ser melhor tentar dividir os dados usando os últimos d dias para teste e o restante para treinamento, ou algo mais próximo do caso de uso para o qual o modelo está sendo construído.
De certa forma, temos uma abordagem de aprendizado supervisionado, uma vez que estamos tentando prever dados rotulados. Mas, como mencionado antes, é anormal no sentido de que um rótulo "verdadeiro" no feedback implícito pode não corresponder ao usuário realmente ter gostado do item. A ruiva pode não ter gostado de Shrek, embora isso seja desconhecido para nós. Por outro lado, ela pode gostar de "Memento", mas não tinha conhecimento desse filme.
Mas isso é o melhor que podemos fazer com os dados que temos. Depois que os dados forem rotulados, as suposições feitas e tivermos uma divisão de teste e trem, podemos ver como modelar nossos problemas.
🤖 Abordagens
Existem duas abordagens principais quando se trata de sistemas de recomendação - content based filtering e collaborative filtering.
Content based filtering
A ideia é usar as informações dos usuários para fazer previsões sobre se ele gostará no futuro. Essas informações podem incluir informações pessoais e informações de compras anteriores. A única coisa a se considerar é que o recurso está disponível para a maioria dos usuários.
A abordagem pode ser resumida a qualquer configuração de aprendizado supervisionado - temos recursos (do usuário e do item) e um rótulo que queremos prever. A partir daí, podemos usar qualquer modelo para classificação - de regressão logística a redes neurais.
Se tivermos um feedback explícito, também poderíamos construir um usuário embedding que tenha recursos no mesmo espaço que os itens, e calcular a semelhança entre eles. Por exemplo, se um usuário definiu que gosta de filmes de ação e drama, podemos procurar filmes de ação e drama.
Mas a ideia geral é ter recomendações específicas para um único usuário - o que ele gosta, em oposição ao collaborative filtering.
Comparação:
- 👍 Escala bem - usa apenas dados de um usuário
- 👍 Posso recomendar interesses de nicho muito específicos - muito específicos para um usuário
- 👎 O modelo é incapaz de explorar e expandir os interesses dos usuários (coisas novas que ele não manifestou interesse no passado)
- 👎 Se o modelo for construído com recursos de engenharia manual, é necessário muito conhecimento de domínio e o modelo é tão bom quanto seus recursos
Collaborative filtering
Na collaborative filtering, não usamos recursos de usuário ou item. Nós nos concentramos inteiramente em nossa matriz de interação. A principal ideia de alto nível é descobrir o que um usuário vai gostar com base no que usuários semelhantes gostaram no passado.

Ideia principal com collaborative filtering.
Na imagem acima - o emoji de festa seria recomendado para caça-níqueis por ser semelhante ao demônio. Aqui, "usuários semelhantes" são aqueles que compraram os mesmos itens (ou semelhantes) no passado.
No collaborative filtering, olhamos apenas para todas as compras e todos os itens. Então o modelo não liga para o que são os itens e nem os usuários. Tentamos criar embeddings de usuário e item úteis com base nas interações entre usuários e itens - ou seja: a matriz de interação.
Essa é a ideia principal, mas vamos mergulhar no funcionamento desse modelo mais tarde.
Comparação:
- 👍 Nenhum conhecimento necessário - não precisamos saber nada sobre o problema para o qual estamos modelando
- 👍 Pode generalizar interesses e recomendar mais itens novos para um usuário
- 👎 Não dimensiona bem - precisa de todas as interações de todos os itens e todos os usuários
- 👎 Não incluímos quaisquer outros recursos específicos do usuário nem recursos específicos do item
- 👎 Baseamos nosso modelo na matriz de interação - não podemos gerar previsões para usuários sem interação registrada (um novo usuário no varejo online, por exemplo); isso é conhecido como problema de inicialização a frio
Abordagem híbrida
É possível um híbrido entre as duas abordagens. E na maioria dos casos o que é implementado. Em uma visão mais geral, o que é feito é ter os dois modelos lado a lado e pesar suas previsões. Também podemos determinar esses pesos de maneira orientada por dados.
Isso também permite o fallback quando não há dados de interação para um usuário. Nesse caso, nos concentramos na abordagem "content based" até que os dados de interação estejam disponíveis.
Uma implementação muito popular e fácil de usar é o modelo LightFM, que é conhecido por alcançar resultados muito bons.
🤔 Avaliação
Como se poderia imaginar, técnicas de avaliação de aprendizagem supervisionada podem ser aplicadas aqui, incluindo curvas de sustentação, ganhos cumulativos, entre outros. No entanto, como se espera que forneçamos ao usuário um conjunto de recomendações e não nos importamos necessariamente com previsões de baixa classificação, outros métodos de avaliação que diferem das abordagens tradicionais se aplicam.
As métricas populares incluem precisão superior @k, precisão @k e recall @k. K é o número de itens que recomendamos a um usuário (no exemplo inicial, usei k = 10). A ideia é calcular as métricas olhando apenas para os K itens mais bem classificados. Tensorflow também oferece essas métricas como uma opção para precisão regular e métricas de recall.
Também é possível avaliar que gama de itens estão sendo recomendados - para evitar modelos em que apenas um subconjunto de todos os itens aparecem como recomendações. Ou personalização - evite que os itens mais populares acabem como recomendações. Recmetrics oferece algumas idéias para avaliação de motores de recomendação.
💁♂️ Collaborative filtering
⚠️ Agora vamos mergulhar na matemática ⚠️
Fatoração de matriz
Matematicamente falando, é uma ideia bastante direta - podemos fatorar a matriz de interação para obter os embeddings para os itens e usuários.
Semelhante à fatoração normal, estamos procurando as matrizes $U$ (para usuários) e $I$ (para itens) que, quando multiplicadas, geram a matriz de interação $R$ (para avaliações), ou
$$U \cdot I = R$$
Observe que $\cdot$ denota multiplicação de matrizes e que as matrizes $U$ e $I$ podem variar em suas dimensões dependendo do tamanho de seu vetor de incorporação.

Exemplo de matriz de interação e matrizes de usuário (à esquerda) e item (em cima). O tamanho de incorporação neste exemplo é 2. Imagem de Google Developers.
ML
Agora que sabemos o que queremos, como podemos implementar a solução?
É aqui que o aprendizado de máquina entra em ação. Aproximamos essas matrizes $U$ e $I$ com base em exemplos. Começamos com valores aleatórios para $U$ e $I$, produzindo um conjunto aleatório de números para $R_{pred}$, a matriz de interação aproximada. Podemos comparar $R_ {actual}$ e $R_ {pred}$ usando qualquer função de perda (pode pensar em algo como entropia cruzada binária , mas somando para cada elemento na matriz) e iterar usando qualquer algoritmo de otimização (pode pensar em "gradient descent"), alterando $U$ e $I$ incrementalmente para chegar mais perto de $R_ {real}$.
Depois de muitas iterações, devemos ter algo semelhante a

A matriz de interação real à esquerda ($R_ {real}$) e a matriz aproximada, ou prevista, dadas as matrizes treinadas $U$ e $I$ ($R_ {pred}$). Imagem de Google Developers.
Depois de muitas iterações, a matriz converge na aproximação das interações reais e podemos produzir os itens com as pontuações de predição mais altas (que ele ainda não gostou). Voltando para a mulher ruiva, a modelo recomendaria "The Dark Knight Rises".
Existem outras alternativas alternativas como para perdas e algoritmos de otimização, que podem convergir mais rapidamente, mas podem ser mais caros computacionalmente, como os mínimos quadrados alternados ponderados (WALS). Os Google Developers oferecem uma comparação geral entre o "gradient descent" e o WALS. Continuaremos com a "gradient descent" assim que falaremos sobre redes neurais.
Isso faz sentido?
Por que isso faz sentido com o que descrevemos acima?
Para tornar as coisas mais simples, digamos que os encaixes dos itens sejam fixos. É mais fácil ver que, se dois usuários com comportamento muito semelhante, eles acabariam com embeddings semelhantes e, portanto, um item apreciado por um usuário seria recomendado ao outro.
🧠 Neural collaborative filtering
Parte "Neural"
A principal adição que temos nesta parte é incluir uma rede neural com esses embeddings que criamos. Isso não é diferente do processo de criação de embeddings de palavras com redes neurais. Nós aproximamos os embeddings aleatórios inicializados com base nos rótulos, usando retropropagação. É interessante adicionar funções não lineares às camadas da rede, uma vez que o "collaborative filtering" "vanilla" já cuida das combinações lineares entre os embeddings de usuário e item (no produto matriz).
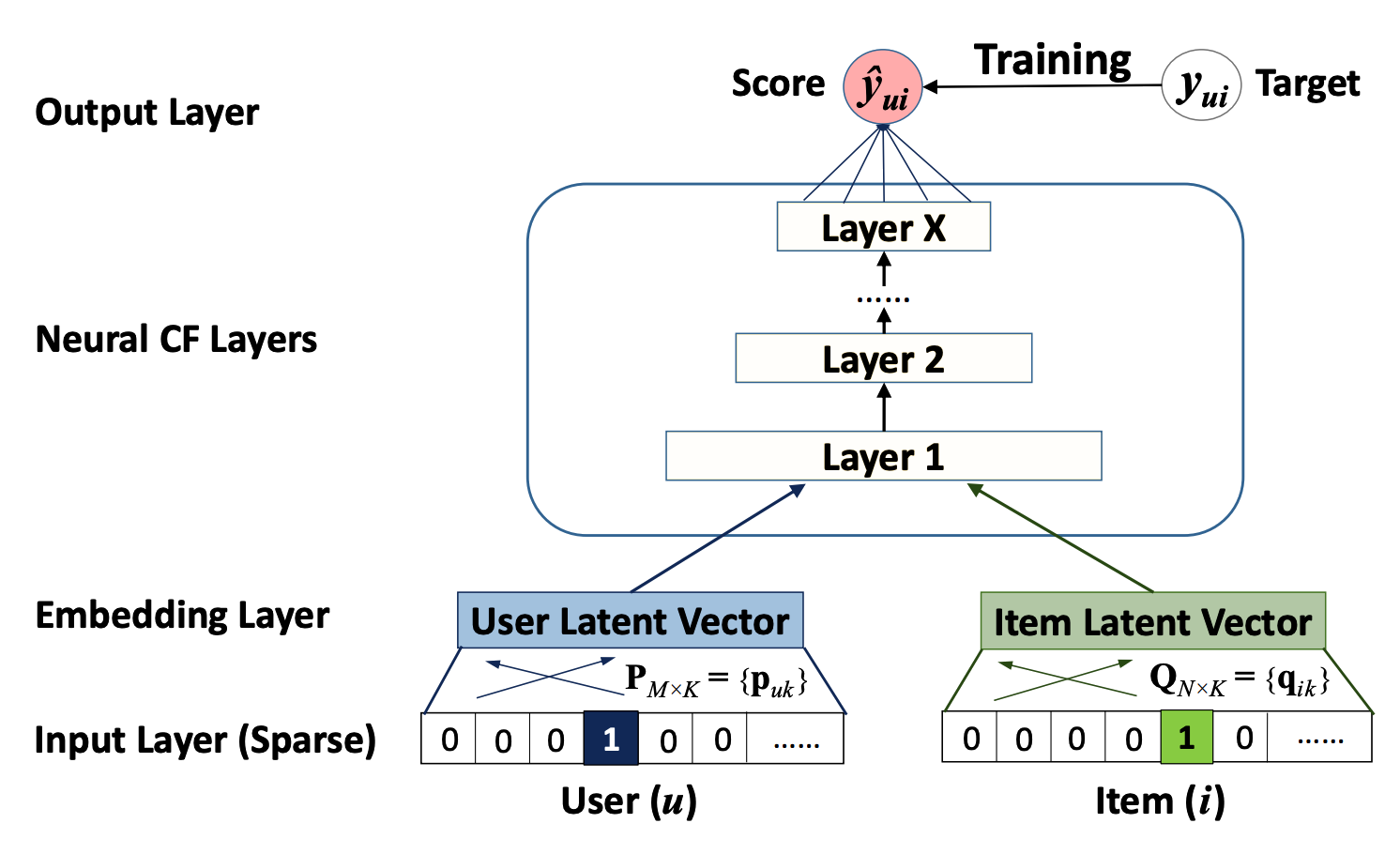
Rede neural para "collaborative filtering", com base no usuário e embeddings de itens. Na camada de entrada, $u$ e $i$ são uma codificação ativa que representa o índice desse usuário. Imagem do artigo Neural Collaborative Filtering.
Pode-se notar que as representações aqui serão diferentes daquelas encontradas no "collaborative filtering" "vanilla". A ideia não é "substituir", mas "adicionar". Podemos realizar a fatoração da matriz como uma rede neural, concatenar as camadas finais e passá-las por uma camada final que produzirá as previsões. Todos juntos, vai parecer
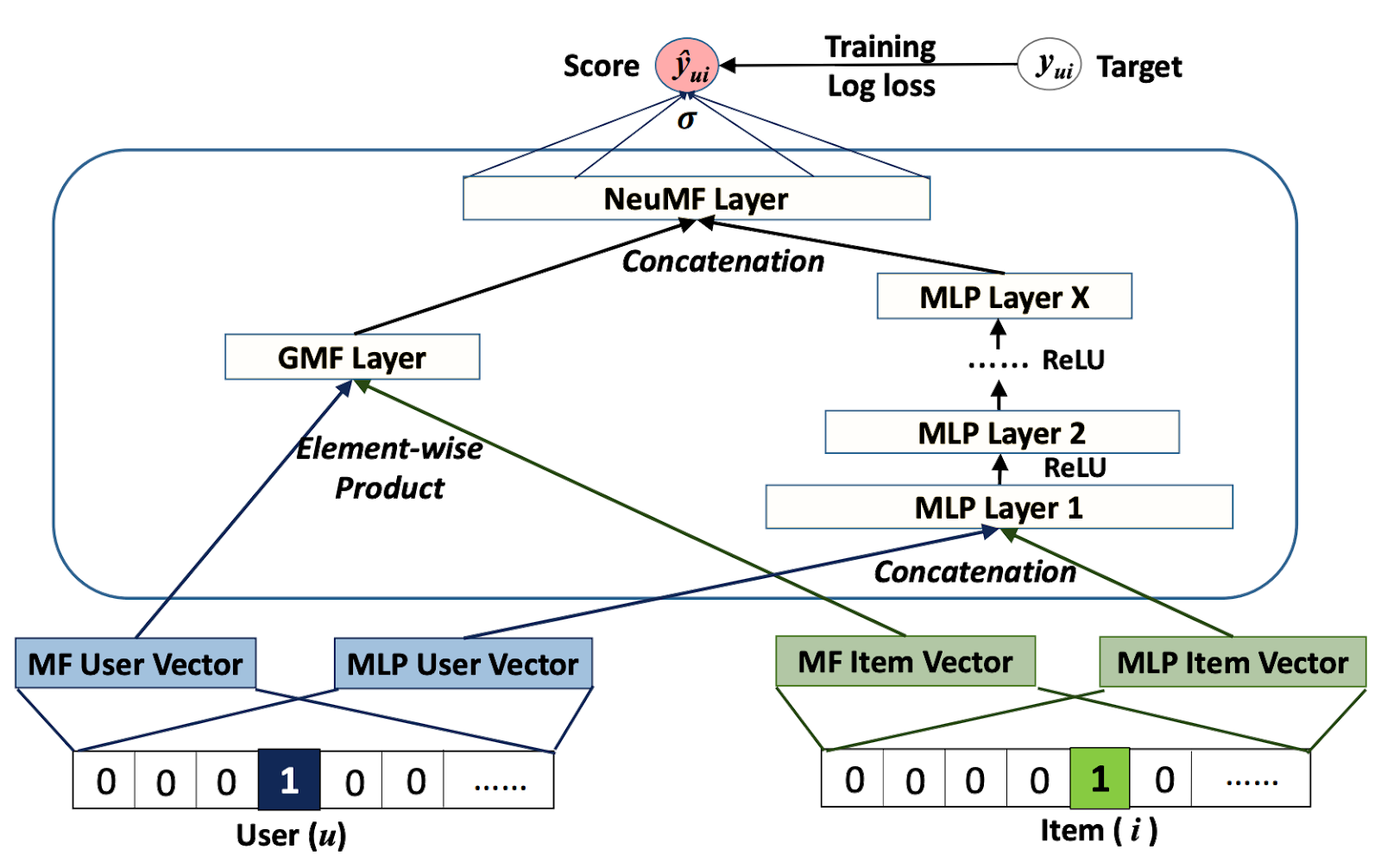
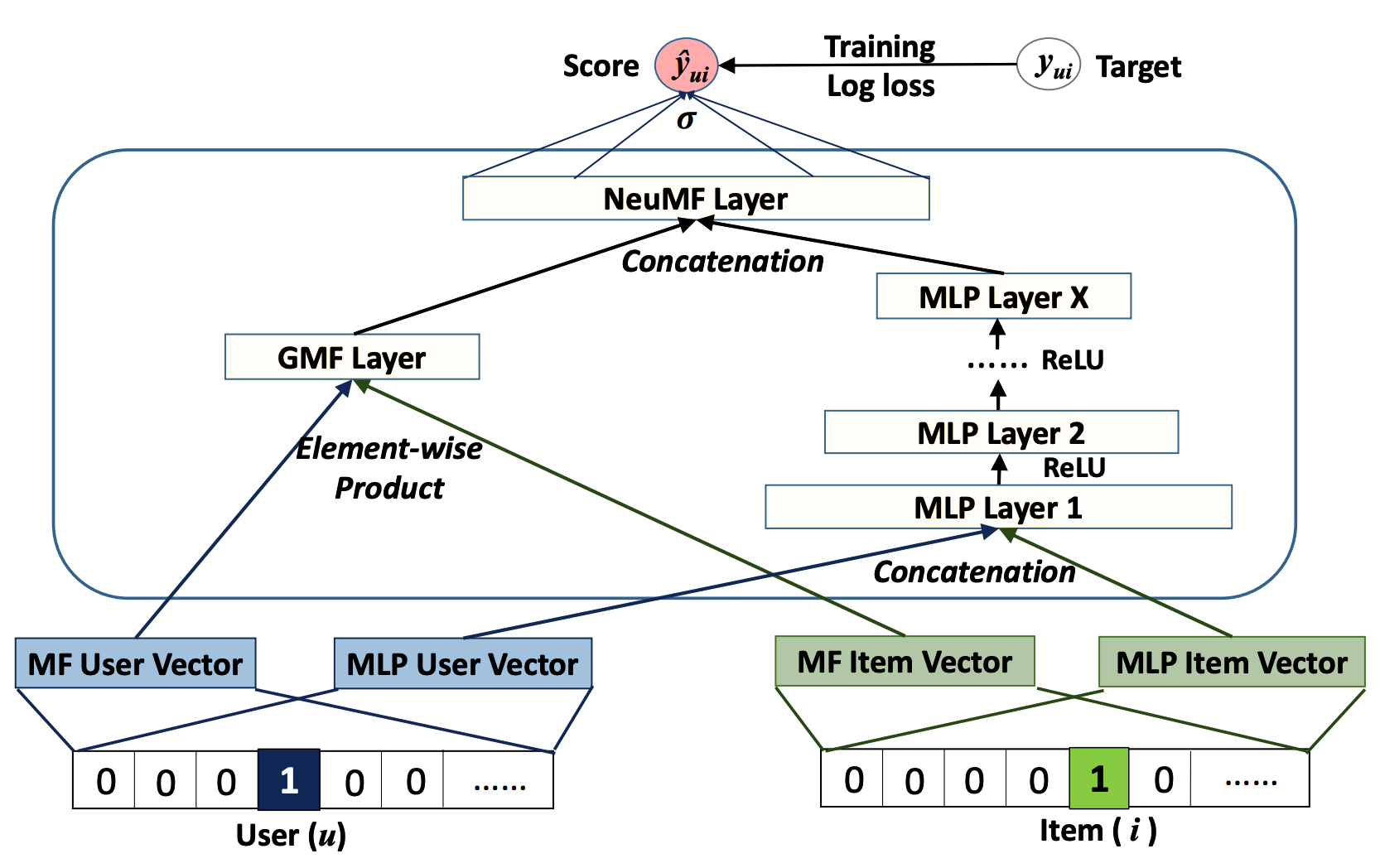
Arquitetura neural colaborativa. Imagem do artigo Neural Collaborative Filtering.
Esses dois modelos diferentes juntos formam a arquitetura geral. Eles podem, no entanto, ser treinados separadamente e ajustados no final (aprendizagem por transferência). Isso pode acelerar o tempo de treinamento e produzir melhores resultados.
💪 Ganhos
A questão é: a complexidade adicional vale a pena?
Ao comparar experimentalmente os resultados usando o conjunto de dados MovieLens, os resultados entre o LightFM e o neural collaborative filtering foram semelhantes (sinta-se à vontade para dar uma olhada na demo!), com um custo computacional consideravelmente maior para redes neurais.
Mas, por outro lado, obtemos mais flexibilidade com o modelo. Além do mais, podemos integrar facilmente um modelo de content based filtering (usando redes neurais) para formar um sistema de recomendação híbrido no Tensorflow. E a complexidade dos problemas que podem ser resolvidos também aumenta - problemas complexos de PNL ou de série temporal podem ser integrados. Poderíamos, por exemplo, alavancar modelos pré-treinados como o BERT e integrá-los neste sistema híbrido de recomendação.
💻 Demo
Caso esteja rodando o notebook não esqueça de fazer o download das bibliotecas e inicie o tensorboard no background:
No terminal
pip install tensorflow lightfm pandas
tensorboard --logdir 2020-09-11-neural_collaborative_filter/logs
ou no notebook
!pip install tensorflow lightfm pandas
%load_ext tensorboard
!tensorboard --logdir 2020-09-11-neural_collaborative_filter/logs &
# collapse
for dataset in ["test", "train"]:
data[dataset] = (data[dataset].toarray() > 0).astype("int8")
# Make the ratings binary
print("Interaction matrix:")
print(data["train"][:10, :10])
print("\nRatings:")
unique_ratings = np.unique(data["train"])
print(unique_ratings)
from typing import List
def wide_to_long(wide: np.array, possible_ratings: List[int]) -> np.array:
"""Go from wide table to long.
:param wide: wide array with user-item interactions
:param possible_ratings: list of possible ratings that we may have."""
def _get_ratings(arr: np.array, rating: int) -> np.array:
"""Generate long array for the rating provided
:param arr: wide array with user-item interactions
:param rating: the rating that we are interested"""
idx = np.where(arr == rating)
return np.vstack(
(idx[0], idx[1], np.ones(idx[0].size, dtype="int8") * rating)
).T
long_arrays = []
for r in possible_ratings:
long_arrays.append(_get_ratings(wide, r))
return np.vstack(long_arrays)
long_train = wide_to_long(data["train"], unique_ratings)
df_train = pd.DataFrame(long_train, columns=["user_id", "item_id", "interaction"])
import tensorflow.keras as keras
from tensorflow.keras.layers import (
Concatenate,
Dense,
Embedding,
Flatten,
Input,
Multiply,
)
from tensorflow.keras.models import Model
from tensorflow.keras.regularizers import l2
def create_ncf(
number_of_users: int,
number_of_items: int,
latent_dim_mf: int = 4,
latent_dim_mlp: int = 32,
reg_mf: int = 0,
reg_mlp: int = 0.01,
dense_layers: List[int] = [8, 4],
reg_layers: List[int] = [0.01, 0.01],
activation_dense: str = "relu",
) -> keras.Model:
# input layer
user = Input(shape=(), dtype="int32", name="user_id")
item = Input(shape=(), dtype="int32", name="item_id")
# embedding layers
mf_user_embedding = Embedding(
input_dim=number_of_users,
output_dim=latent_dim_mf,
name="mf_user_embedding",
embeddings_initializer="RandomNormal",
embeddings_regularizer=l2(reg_mf),
input_length=1,
)
mf_item_embedding = Embedding(
input_dim=number_of_items,
output_dim=latent_dim_mf,
name="mf_item_embedding",
embeddings_initializer="RandomNormal",
embeddings_regularizer=l2(reg_mf),
input_length=1,
)
mlp_user_embedding = Embedding(
input_dim=number_of_users,
output_dim=latent_dim_mlp,
name="mlp_user_embedding",
embeddings_initializer="RandomNormal",
embeddings_regularizer=l2(reg_mlp),
input_length=1,
)
mlp_item_embedding = Embedding(
input_dim=number_of_items,
output_dim=latent_dim_mlp,
name="mlp_item_embedding",
embeddings_initializer="RandomNormal",
embeddings_regularizer=l2(reg_mlp),
input_length=1,
)
# MF vector
mf_user_latent = Flatten()(mf_user_embedding(user))
mf_item_latent = Flatten()(mf_item_embedding(item))
mf_cat_latent = Multiply()([mf_user_latent, mf_item_latent])
# MLP vector
mlp_user_latent = Flatten()(mlp_user_embedding(user))
mlp_item_latent = Flatten()(mlp_item_embedding(item))
mlp_cat_latent = Concatenate()([mlp_user_latent, mlp_item_latent])
mlp_vector = mlp_cat_latent
# build dense layers for model
for i in range(len(dense_layers)):
layer = Dense(
dense_layers[i],
activity_regularizer=l2(reg_layers[i]),
activation=activation_dense,
name="layer%d" % i,
)
mlp_vector = layer(mlp_vector)
predict_layer = Concatenate()([mf_cat_latent, mlp_vector])
result = Dense(
1, activation="sigmoid", kernel_initializer="lecun_uniform", name="interaction"
)
output = result(predict_layer)
model = Model(
inputs=[user, item],
outputs=[output],
)
return model
# collapse
from tensorflow.keras.optimizers import Adam
n_users, n_items = data["train"].shape
ncf_model = create_ncf(n_users, n_items)
ncf_model.compile(
optimizer=Adam(),
loss="binary_crossentropy",
metrics=[
tf.keras.metrics.TruePositives(name="tp"),
tf.keras.metrics.FalsePositives(name="fp"),
tf.keras.metrics.TrueNegatives(name="tn"),
tf.keras.metrics.FalseNegatives(name="fn"),
tf.keras.metrics.BinaryAccuracy(name="accuracy"),
tf.keras.metrics.Precision(name="precision"),
tf.keras.metrics.Recall(name="recall"),
tf.keras.metrics.AUC(name="auc"),
],
)
ncf_model._name = "neural_collaborative_filtering"
ncf_model.summary()
def make_tf_dataset(
df: pd.DataFrame,
targets: List[str],
val_split: float = 0.1,
batch_size: int = 512,
seed=42,
):
"""Make TensorFlow dataset from Pandas DataFrame.
:param df: input DataFrame - only contains features and target(s)
:param targets: list of columns names corresponding to targets
:param val_split: fraction of the data that should be used for validation
:param batch_size: batch size for training
:param seed: random seed for shuffling data - set to `None` to not shuffle"""
n_val = round(df.shape[0] * val_split)
if seed:
# shuffle all the rows
x = df.sample(frac=1, random_state=seed).to_dict("series")
else:
x = df.to_dict("series")
y = dict()
for t in targets:
y[t] = x.pop(t)
ds = tf.data.Dataset.from_tensor_slices((x, y))
ds_val = ds.take(n_val).batch(batch_size)
ds_train = ds.skip(n_val).batch(batch_size)
return ds_train, ds_val
# create train and validation datasets
ds_train, ds_val = make_tf_dataset(df_train, ["interaction"])
%%time
# define logs and callbacks
logdir = os.path.join("logs", datetime.datetime.now().strftime("%Y%m%d-%H%M%S"))
tensorboard_callback = tf.keras.callbacks.TensorBoard(logdir, histogram_freq=1)
early_stopping_callback = tf.keras.callbacks.EarlyStopping(
monitor="val_loss", patience=0
)
train_hist = ncf_model.fit(
ds_train,
validation_data=ds_val,
epochs=N_EPOCHS,
callbacks=[tensorboard_callback, early_stopping_callback],
verbose=1,
)
long_test = wide_to_long(data["train"], unique_ratings)
df_test = pd.DataFrame(long_test, columns=["user_id", "item_id", "interaction"])
ds_test, _ = make_tf_dataset(df_test, ["interaction"], val_split=0, seed=None)
%%time
ncf_predictions = ncf_model.predict(ds_test)
df_test["ncf_predictions"] = ncf_predictions
# collapse
data["ncf_predictions"] = df_test.pivot(
index="user_id", columns="item_id", values="ncf_predictions"
).values
print("Neural collaborative filtering predictions")
print(data["ncf_predictions"][:10, :4])
precision_ncf = tf.keras.metrics.Precision(top_k=TOP_K)
recall_ncf = tf.keras.metrics.Recall(top_k=TOP_K)
precision_ncf.update_state(data["test"], data["ncf_predictions"])
recall_ncf.update_state(data["test"], data["ncf_predictions"])
print(
f"At K = {TOP_K}, we have a precision of {precision_ncf.result().numpy():.5f}",
f"and a recall of {recall_ncf.result().numpy():.5f}",
)
%%time
# LightFM model
def norm(x: float) -> float:
"""Normalize vector"""
return (x - np.min(x)) / np.ptp(x)
lightfm_model = LightFM(loss="warp")
lightfm_model.fit(sparse.coo_matrix(data["train"]), epochs=N_EPOCHS)
lightfm_predictions = lightfm_model.predict(
df_test["user_id"].values, df_test["item_id"].values
)
df_test["lightfm_predictions"] = lightfm_predictions
wide_predictions = df_test.pivot(
index="user_id", columns="item_id", values="lightfm_predictions"
).values
data["lightfm_predictions"] = norm(wide_predictions)
# compute the metrics
precision_lightfm = tf.keras.metrics.Precision(top_k=TOP_K)
recall_lightfm = tf.keras.metrics.Recall(top_k=TOP_K)
precision_lightfm.update_state(data["test"], data["lightfm_predictions"])
recall_lightfm.update_state(data["test"], data["lightfm_predictions"])
print(
f"At K = {TOP_K}, we have a precision of {precision_lightfm.result().numpy():.5f}",
"and a recall of {recall_lightfm.result().numpy():.5f}",
)